Final_Project
Final_Project
Problem Statement that introduces your selected topic, identifies significant goals associated with the implementation of your applied machine learning method, demonstrates why your problem is important, and describes and analyzes the complex nature of your problem including any process oriented causes and effects. Conclude your problem statement with a stated central research question. You are welcome to articulate a central research question in broad and general terms, given the abbreviated time frame for this investigation.
Problem Statement:
Can we train a ML model on easily collected health features that would help to predict the mortality risk of individuals with/without cardiovascular disease? Every year millions of people lose their lives to cardiovascular disease/heart failure due to many different factors but mostly because of poor health. In the US heart failure is the leading cause of death in adults. As the leading cause of death in the US, being able to predict the likelihood of death by heart failure before it happens would be extremely beneficial. This kind of model would be useful to health care providers and patients alike when it comes to assessing the severity of their heart condition whether or not they know if they have one.
At first i wanted to look at using machine learning algorithms to forecast sales data but due to not finding an appropriate dataset i decided to switch to predicting stock prices instead. While there is an abundance of stock price data available i eventually decided that there were too many external factors that go into the daily price movements that affect individual stocks. After this i decided to try making a sentiment analysis classifier, which i did, but then realized afterwards that my research problem statement was not compatible with the dataset that i was using. So i finally decided to make heart failure predictors using a linear classifier, a sequential model, and a boosted trees model.
Data description:
This dataset was obtained from Kaggle and you can find it in the link above. The original sources of this data are from the Faisalabad Institute of Cardiology and the Allied Hospital in Faisalabad Pakistan. There are a total of 300 rows in the entire dataset although a larger dataset would have been preferred. Furthermore there are 13 columns of which i will be using 12 since the column ‘time’ is not relevant to the desired goal. This data comes from a study where cardiovascular disease patients were observed for a number of days before they either left the study or passed away. The column names are:
'age', 'anaemia', 'creatinine_phosphokinase', 'diabetes',
'ejection_fraction', 'high_blood_pressure', 'platelets',
'serum_creatinine', 'serum_sodium', 'sex', 'smoking', 'time',
'DEATH_EVENT'
The columns ‘anaemia’, ‘high_blood_pressure’, ‘sex’, and ‘smoking’ are the only categorical variables in the dataset, the others are continuous. The target column is ‘DEATH_EVENT’. ‘0’ means no recorded death and ‘1’ indicates a death. This dataset suffers from class imbalance due to the number of deaths making up only about 32% of the dataset. People leaving the study earlier than others counts as a non-death event which adds further inaccuracy to our model results.
Model Specifications
Provide the specification for your applied machine learning method that presented the most promise in providing a solution to your problem. Include the section from your python or R script that specifies your model architecture, layers, functional arguments and specifications for compiling and fitting. Provide a brief description of how you implemented your code in practice.
I decided to do a linear classifier model, boosted trees model, and a sequential model. From the beginning i figured that the boosted trees model would outperform the linear classifier and it did. The linear classifier was the worst performing model out of the three.
LINEAR REGRESSION
linear_est = tf.estimator.LinearClassifier(feature_columns) #logistic regression model
linear_est.train(train_input_fn, max_steps=100)
result = linear_est.evaluate(eval_input_fn)
Results for the linear classifier:
accuracy 0.633333
accuracy_baseline 0.633333
auc 0.506380
auc_precision_recall 0.379209
average_loss 489.733337
label/mean 0.366667
loss 489.733337
precision 0.500000
prediction/mean 0.022222
recall 0.030303
global_step 100.000000
dtype: float64
BOOSTED TREES
n_batches = 1
est = tf.estimator.BoostedTreesClassifier(
feature_columns, n_batches_per_layer=n_batches)
est.train(train_input_fn, max_steps=100)
result = est.evaluate(eval_input_fn)
Results for the boosted trees model:
accuracy 0.766667
accuracy_baseline 0.633333
auc 0.803828
auc_precision_recall 0.651946
average_loss 0.600108
label/mean 0.366667
loss 0.600108
precision 0.730769
prediction/mean 0.310273
recall 0.575758
global_step 100.000000
dtype: float64
Sequential Model Architecture:
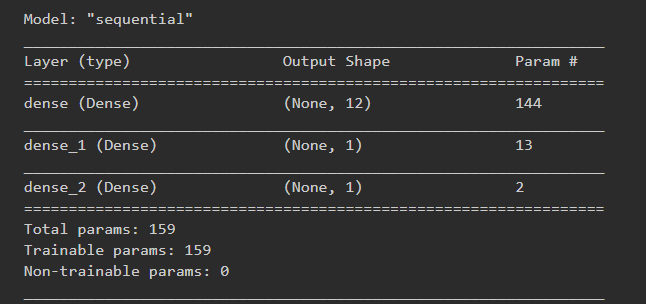
Results for Sequential Model:
Epoch 10/10
209/209 [==============================] - 0s 771us/step - loss: 0.6459 - accuracy: 0.6537
The model accuracy score is 0.63 which was calculated using model.evaluate.
Conclusion
Conclude with a section that preliminarily assesses model performance. If you have results from your implementation, you are welcome to add those in this section. Compare your preliminary results with those from the literature on your topic for a comparative assessment. If you are not able to produce preliminary results, provide a cursory literature review that includes 2 sources that present and describes their validation. With more time and project support, estimate what an ideal outcome looks like in terms of model validation.
The accuracy on my best performing model was 0.767. These scores were reached without standardizing the data so there is much room for improvement. My preliminary results are below the accuracy levels of the various models tested in Tripoliti et al. which were in the 80s and 90s for model accuracy. So in terms of an ideal outcome, it would be best to get model accuracy to at least 90%.
References